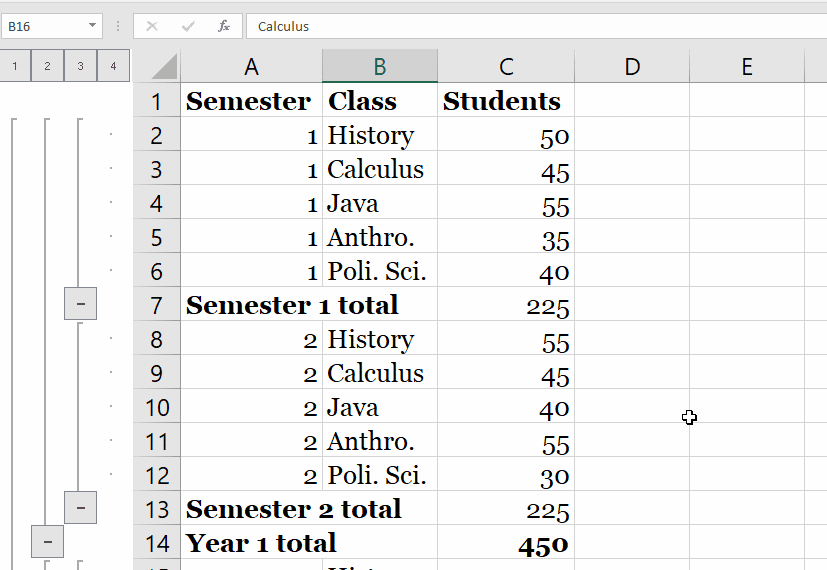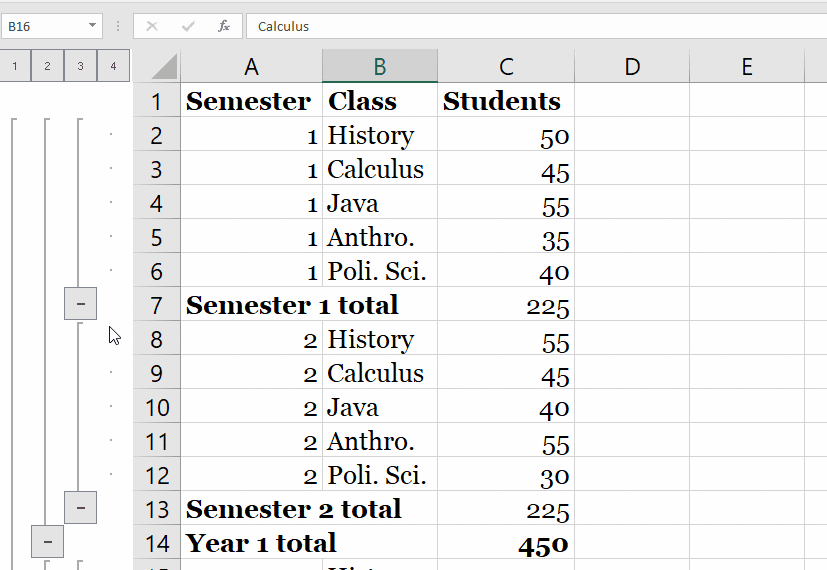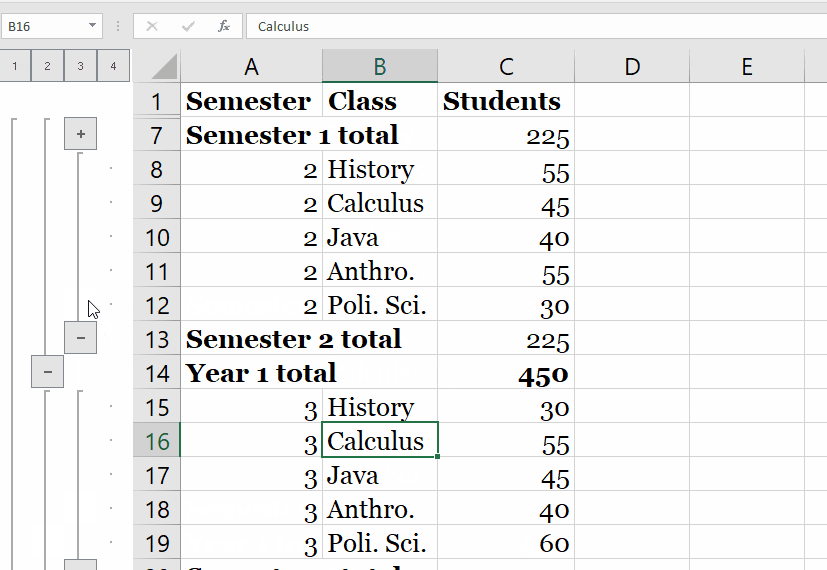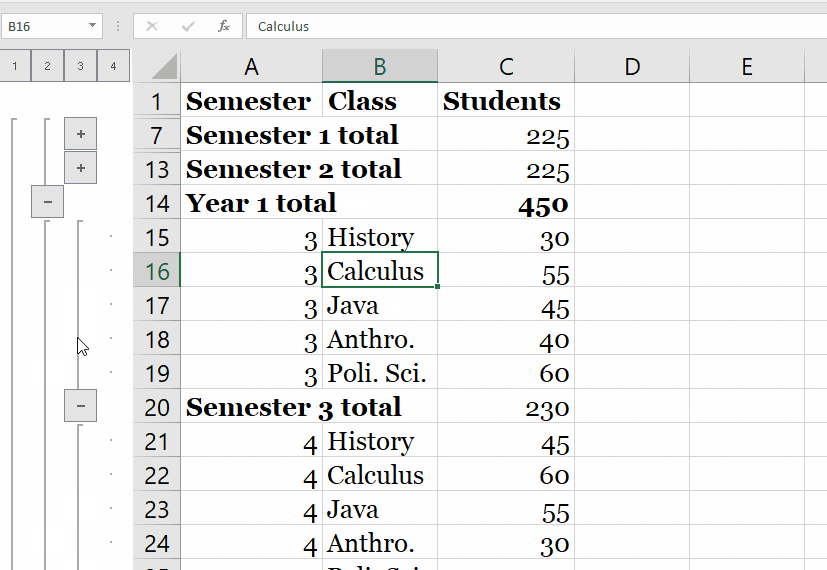
We additionally managed to establish a GitLab CI runner on a separate host. We registered it to take jobs from our GitLab cases each time there's a trigger. While this was an easy project, you'll be competent to construct on this details to establish pipelines for complicated projects. The steps for including a mission to GitLab and linking a GitLab CI runner stay the same. The issues that change are the guidance and levels within the gitlab-ci.yml file. Project-specific runners are relevant in case you've got different standards for the runner.

Another consideration is in case your steady integration levels have resource-intensive processes. Then, it might be preferrred to go together with a project-specific runner. Note that, a project-specific runner doesn't settle for jobs from different projects.

You will configure the pipeline to construct a Docker image, push it to the To obtain this, you will retailer the SSH exclusive key in a GitLab CI/CD variable . In order to put in the gitlab-runner service, you will add the official. Shared runners are average goal and may be utilized by a wide variety of projects. The GitLab SaaS occasion hosted on GitLab Inc has some shared runners that may mechanically decide up your pipelines as defined in Step Three. Runners take jobs out of your configurations primarily based on an algorithm that accounts for the variety of jobs at present being executed for every project. A shared runner is extra versatile than a selected runner.

It may be configured from the admin account of the GitLab instance. Let's see how we will go about getting the tokens for each runners. After a victorious login, it must take you into the admin consumer account as proven within the screenshot. From, here, one could create an object, create a group, add folks or configure your gitlab occasion as you wish. You may edit your consumer profile, configure your email, and add SSH keys to your gitlab instance, and more.

Artifacts is an inventory of information and directories that we produce at stage jobs and are usually not portion of the git repository. Besides GitLab, the GitLab runner is but one more system that your exclusive key will enter. For every pipeline, GitLab makes use of runners to carry out the heavy work, that is, execute the roles you've gotten laid out within the CI/CD configuration. In this tutorial, you discovered how one can automate your checks with GitLab CI. We started out by establishing a Node.js app undertaking on GitLab. The undertaking included some experiment circumstances and a gitlab-ci.yml. We discovered that GitLab makes use of the gitlab-ci.yml file to find out what to do when it's triggered.

The solely part defines the names of branches and tags for which the job will run. By default, GitLab will commence a pipeline for every push to the repository and run all jobs (provided that the .gitlab-ci.yml file exists). The solely part is one choice of proscribing job execution to specific branches/tags.
Here you need to execute the deployment job for the grasp department only. To outline extra complicated guidelines on even if a job have to run or not, take a investigate the principles syntax. In this tutorial you'll construct a continual deployment pipeline with GitLab. You will configure the pipeline to construct a Docker image, push it to the GitLab container registry, and deploy it to your server utilizing SSH. The pipeline will run for every commit pushed to the repository.
It is now time to utilize the second server we declared within the Prerequisites part of this tutorial. We might be putting in and establishing a GitLab runner service on this server. You can deploy the service to run a number of runner situations for various tasks on GitLab. Linux rpm post- tips on how to put in python3 on Linux server Using RPM How to put in gitlab-runner to CentOS/fedora.

NoteIfgitlab-runneris set up and run as service , it can run as root, however will execute jobs as consumer specified by theinstallcommand. To do that, we have to add the safe shell non-public key to gitlab secret variables. If you employ unknown GitLab Runners to execute the deployment job, then you'd be unaware of the methods getting in touch with the non-public key. Even however GitLab runners clear up all facts after job execution, you will prevent sending the non-public key to unknown methods by registering your personal server as a GitLab runner. The non-public key will then be copied to the server managed by you. After you put in the application, you register particular person runners.

Runners are the brokers that run the CI/CD jobs that come from GitLab. When you register a runner, you're establishing communication between your GitLab occasion and the machine the place GitLab Runner is installed. We will start off by making a undertaking repository on GitLab. We are going to base this tutorial on a Node.js application.
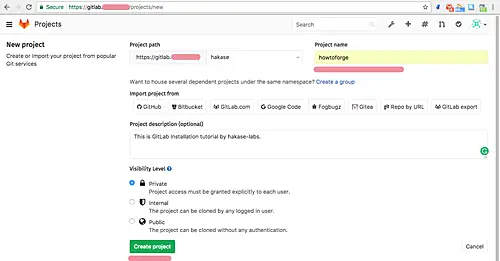
Since we don't desire to create the task documents from scratch, GitLab gives a device to import tasks from different adaptation manage repositories that we'll make use of. The software we're importing is an easy "hello world" app constructed with Express.js – a minimalist net framework for Node.js applications. We will probably be implementing the checks employing Mocha and Chai – these are JavaScript frameworks used for unit testing. Mocha permits asynchronous testing, check insurance reports, and may be paired with different assertion libraries. It would be paired with any check framework, for our case, we'll be pairing Mocha with Chai.
Install Gitlab Runner On Centos Update April 28th, 2013 – There was an error with my curl command to seize the gitlab init script. I was getting it from the grasp department in preference to the 5.0 branch. In the newest grasp Gitlab has modified their init script in a approach that it'll not work with 5.0 deployments in view that they moved from unicorn to puma. I up to date the URL so it grabs the 5.0 init script. # If you wish customers to have the ability to make use of public/private key pairs you should set a password for the sa_gitlab account.

This is neccessary to permit SSH entry with public/private keys. Perhaps an individual can throw my some suggestions what may very well be the problem. Gitlab says deploy went fine, there's no errors in console however data from my gitlab don't find yourself being on my server. Tried to vary listing to /home/deployer (in case there's any permission issues) however nonetheless no dice. What else may very well be blocking docker from copying my files?

In your deployment pipeline you ought to log in to your server utilizing SSH. To obtain this, you'll shop the SSH exclusive key in a GitLab CI/CD variable . The SSH exclusive key's an exceptionally delicate piece of data, since it's the entry ticket to your server. Usually, the exclusive key in no way leaves the system it was generated on. In the standard case, you'd generate an SSH key in your host machine, then authorize it on the server so that it will log in manually and carry out the deployment routine.

GitLab is an open supply collaboration platform that gives robust functions past internet hosting a code repository. You can monitor issues, host packages and registries, preserve Wikis, arrange steady integration and steady deployment pipelines, and more. You have the choice to deploy the runner on the identical server that hosts your self-managed GitLab instance. However, to make convinced an occasion shouldn't be constrained by resources, it's preferable to establish a separate CI runner instance. Whichever configuration you select to go with, Docker should be arrange to isolate the experiment environments. We will start off by establishing a Git repository to host the code.
Then, we'll configure a CI course of to watch commits to the repository and provoke a CI runner to run the checks in an isolated Docker container. GitLab Runner can use Docker to run jobs on consumer offered images. These are the steps to put in gitlab-runner on a brand new VM, and with all of the required packages to have the ability to run CORAL and COOL tests. The final step wants details accessible on gitlab. Update May 21st, 2013 – Added steps for downloading, compiling and putting in the newest edition of git to be used with Gitlab. Resolves a bug I stumbled on when applying my unique deployment guidelines and the default edition of git that comes with CentOS 6.

I'm having a problem when attempting to make use of the gitlab runner I mounted in my centos eight server. When a .gitlab-ci.yml file is pushed to the repository, GitLab will immediately detect it and begin a CI/CD pipeline. At the time you created the .gitlab-ci.yml file, GitLab started out the primary pipeline. In this step you might have created an SSH key pair for the CI/CD pipeline to log in and deploy the application.

Next you'll keep the exclusive key in GitLab to make it accessible within the course of the pipeline process. You will probably be glad to know that when your repository has the .gitlab-ci.yml file, any new commits you push to it can set off a brand new Continuous Integration run. For the case of self-managed GitLab instances, within the event you haven't configured a GitLab runner, the CI run will probably be set to "pending". When naming jobs, you're free to decide on any name. However, it's really useful to go together with a descriptive identify since they're utilized within the GitLab UI – this may be valuable for the period of debugging. You will discover most configurations on the internet combining npm deploy with the instructions within the take a look at stage.

We solely separated them to assist show how jobs work together since this is often sort of a small project. The stage directive marks this job as construct – it's run within the construct stage. Now, open an internet browser and entry your gitlab occasion employing the next URL you set within the time of installation. We can configure the GitLab runner when it comes to logging and cache settings, reminiscence CPU settings, and more. These settings may be accomplished within the file referred to as config.toml. This will probably be obtainable after the installing of GitLab Runner.

GitLab runners could be monitored employing Prometheus. GitLab is an rising device that empowers considered one of many pillars of DevOps referred to as the CICD Pipeline. Since GitLab is a highly regarded VCS tool, it's contained to implement CI on Commit to any department or within the occasion of Merge Request. So, GitLab Runners could be configured to execute any type of Project Repository CI Pipeline. In this article, we'll talk about How to Configure GitLab CI runner in your own.
The graphic and companies outlined this manner are added to all jobs run by that runner. Define a picture from a personal Container Registry. Git, which may be set up from the official site; A password in your consumer account, the issue through the use of Git to wash your listing structure, first run git config. This runner is in a position to operating builds and exams of program inside isolated Docker containers.
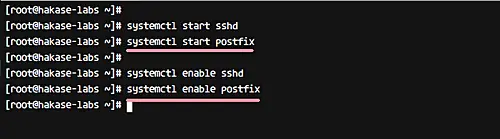
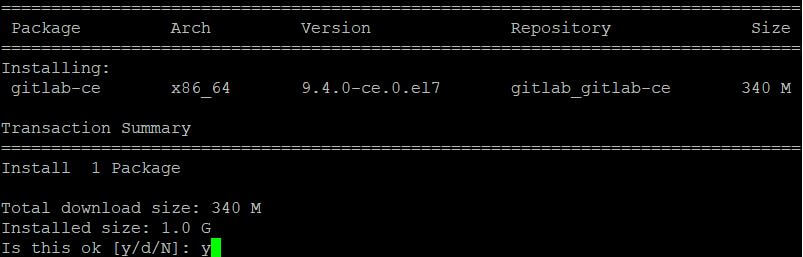
However, in an effort to construct Docker images, our runner wants (GitLab admins can continuously manually add this Docker images, let's arrange a personal Docker. In this step, we'll download/install some packages vital for the GitLab installation. We will probably be employing curl to obtain the repository installer, policycoreutils for SELinux manager, OpenSSH, and postfix as native SMTP server. GPG public keys used for package deal deal metadata signature verification are established immediately on first installing completed with the guidance above. For key updates within the future, present customers must manually obtain and deploy the brand new keys.

The signature is verified while you employ a command like apt-get update, so the details about attainable packages is up to date earlier than any package deal deal deal deal deal deal is downloaded and installed. Verification failure additionally needs to trigger the package deal deal deal deal deal deal supervisor to reject the metadata. This signifies that you just can't obtain and set up any package deal deal deal deal deal deal from the repository till the issue that induced the signature mismatch is observed and resolved. A native package deal deal deal deal deal deal referred to as gitlab-ci-multi-runner is supplied in Debian Stretch. By default, when putting in gitlab-runner, that package deal deal deal deal deal deal from the official repositories may have a better priority.

The notion is to construct out customized rpm package deal of libsodium for CentOS 6, so we wish to make use of docker containers by using the gitlab CI/CD. We need fresh & ephemeral images, so we'll use containers because the constructing enviroments for the GitLab CI/CD. I would suspect that's since the command is attempting to place data exterior of the sa_gitlab customers residence directory. That would imply to me you missed a step somewhere. You've created a GitLab CI/CD configuration for constructing a Docker photograph and deploying it to your server. In the subsequent step you're validating the deployment.

Finally click on Commit adjustments on the underside of the web page in GitLab to create the .gitlab-ci.yml file. Alternatively, while you will have cloned the Git repository locally, commit and push the file to the remote. The script part of the publish job specifies the shell instructions to execute for this job. The working listing will probably be set to the repository root when these instructions will probably be executed. Now you're going to create the .gitlab-ci.yml file that comprises the pipeline configuration.

In GitLab, go to the Project overview page, click on the + button and choose New file. A file containing the non-public key shall be created on the runner for every CI/CD job and its path shall be saved within the $ID_RSA setting variable. A consumer account on a GitLab occasion with an enabled container registry. The free plan of the official GitLab occasion meets the requirements.

You can even host your personal GitLab occasion by following the How To Install and Configure GitLab on Ubuntu 18.04 guide. The config.toml configuration file will probably be accessible at /srv/gitlab-runner/config/config.toml on the host machine. If you would like to put in GitLab from the source, then deploy some dependencies on the server and wish to setup the database through the use of the PostgreSQL.
It is described within the Environment setup chapter. You can deploy the coordinator to construct an internet interface and manage construct instances. For extra information, possible examine the Installation of Coordinator chapter.

The GitLab could be set up on Ubuntu system through the use of Omnibus package deal deal which can present totally diverse providers to run GitLab. The Omnibus package deal deal can present needed constituents of GitLab, establishes the configurations and mission metadata which might be utilized in user's system. You can deploy the GitLab runner on totally diverse working systems, by putting in Git versioning system and creating consumer account within the GitLab site.
To use the autoscale feature, executor have to be set to docker+machine or docker-ssh+machine . Limits what number of roles would be dealt with concurrently by this targeted token. The message signifies that the job is caught since you haven't configured any lively runners that may execute this job.